Gardencam
Some time ago I had the idea to stick a camera out a window, take a photo every few minutes, and stitch them together as a matrix that with a bit of luck would visualise the seasons.
Thus:
- Raspberry Pi Zero, with camera.
- Mounting board that sticks to a window (I used this)
- A script (/capture.sh ?)
We will want to access the images in a grid with rows according to day in year, and columns by minute in day, so name the image thus to make retrieval simpler.
#!/bin/bash
set -ex
H=$(date "+%H" -u)
M=$(date "+%M" -u)
declare -i MM
MM="$H*60+$M"
FM=$(printf "%04d" $MM)
D=images/$(date "+%0Y-%0j-$FM" -u).jpg
echo H=$H, M=$M, MM=$MM, D=$D >> /home/jbu/log
raspistill -n --ISO 100 --exposure auto --mode 7 -r -e jpg -o ${D}
gsutil -m rsync images gs://gardencam/images && rm images/*
You will have needed to go through the gcloud auth login thing.
Edit the crontab:
*/5 * * * * /capture.sh
And then leave it going for months, slowly forgetting it's there.

So months later, what do we have? Well, lots of images, but what do they look like as the intended matrix visualisation?
I could download all the images to the laptop and do it there, but it's holidays so time to shuck fit up and try something new. Google now runs Jupiter notebooks for you, with a nice docs-like interface (colab.research.google.com). So imagine this is in a notebook:
from google.colab import auth
auth.authenticate_user() # so we can connect to the storage bucket
from google.cloud import storage
storage_client = storage.Client(project='xxxx')
bucket = storage_client.get_bucket('xxxx')
all_names = [(b, *map(int, b.name[:-4].split('-')[-2:]))
for b in bucket.list_blobs()]
So now we have all the names, with day and time for column and row. We then want to cut this down to something reasonable, so let's gather all the day and time values, decide how many rows and columns we want, and adjust things to suit that.
cols = {r[2] for r in all_names}
rows = {r[1] for r in all_names}
colcount = 60
rowcount = 40
names = [n for n in all_names
if n[1]%(math.floor(len(rows)/rowcount)) == 0
if n[2]%(math.floor(len(cols)/colcount)) == 0]
cols = sorted(list({r[2] for r in names}))
rows = sorted(list({r[1] for r in names}))
w = 768
h = 768
xstride = w//len(cols)
ystride = h//len(rows)
Now let's draw something.
import io
from PIL import Image
canvas = Image.new(mode='RGB', size=(w, h), color=(128, 128, 128))
def place(canvas, n):
x = xstride * cols.index(n[2])
y = ystride * rows.index(n[1])
t = n[0].download_as_string()
stream = io.BytesIO(t)
img = Image.open(stream)
img = img.resize((xstride,ystride), Image.BICUBIC)
canvas.paste(img, (x, y))
for n in names[:5]:
place(canvas, n)
canvas
Notice the [:5] there. What we find is that this takes a loooong time to iteratively download and resize hundreds of images. Remember, python is inherently single threaded. Honestly, I got bored and decided to try some shiny new things. Remember, shucking fit up here.
We're going to do this with a 2 stage fix. First, we offload the image loading and resizing to a cloud function. Then we use asyncio to multiplex calling that function. This should give us reasonable scalability.
Rewrite the image drawing loop thusly:
import io
import asyncio
!pip install aiohttp
import aiohttp
from PIL import Image
canvas = Image.new(mode='RGB', size=(w, h), color=(128, 128, 128))
async def place(canvas, n):
async with aiohttp.ClientSession() as session:
u = 'https://europe-west2-xxxx.cloudfunctions.net/resizeimage/{}?w={}&h={}'.format(
n[0].name, xstride, ystride)
tries = 3
x = xstride * cols.index(n[2])
y = ystride * rows.index(n[1])
while tries:
async with session.get(u) as response:
stream = await response.read()
try:
img = Image.open(io.BytesIO(stream))
canvas.paste(img, (x, y))
break
except:
tries = tries - 1
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather( *[place(canvas, n) for n in names]))
canvas
We retry a few times because I was getting some internal errors in the frontend server while the instances scaled.
Then we need a cloud function. I used the google ones, and it was painless and worked well. The function was
import io
from google.cloud import storage
from PIL import Image
import flask
storage_client = storage.Client(project='xxxx')
bucket = storage_client.get_bucket('xxxx')
def resize(request):
image_path = request.path
blob = storage.Blob(image_path[1:], bucket)
t = blob.download_as_string()
stream = io.BytesIO(t)
img = Image.open(stream)
img = img.resize((int(request.args['w']),int(request.args['h'])), Image.BICUBIC)
ostream = io.BytesIO()
img.save(ostream, 'JPEG')
response = flask.make_response(ostream.getvalue())
response.headers['Content-Type'] = 'image/jpeg'
return response
With an associated requirements.txt of
Pillow
google-cloud-storage
I just used the web gui to set all that up. A little more speedy:
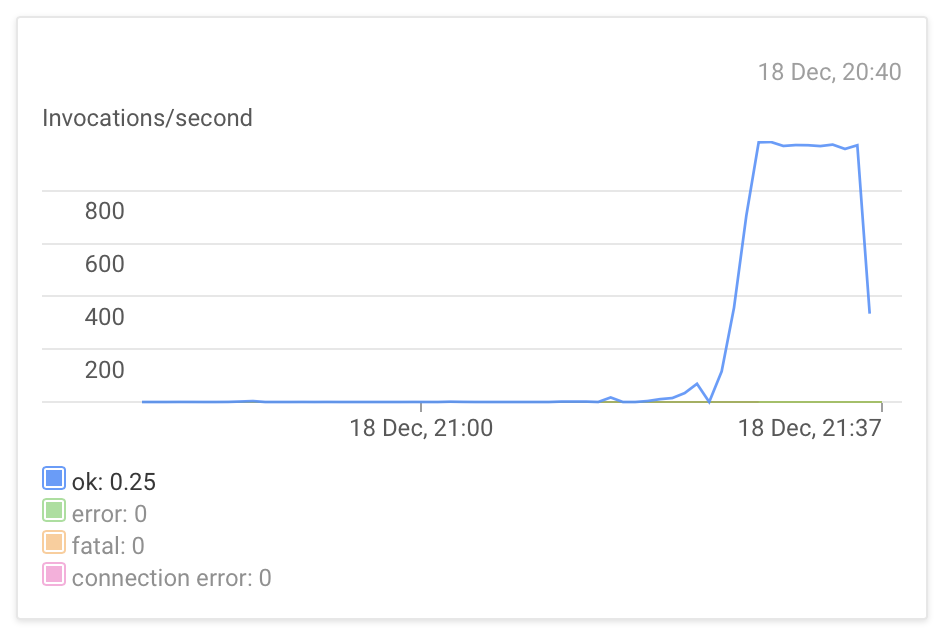
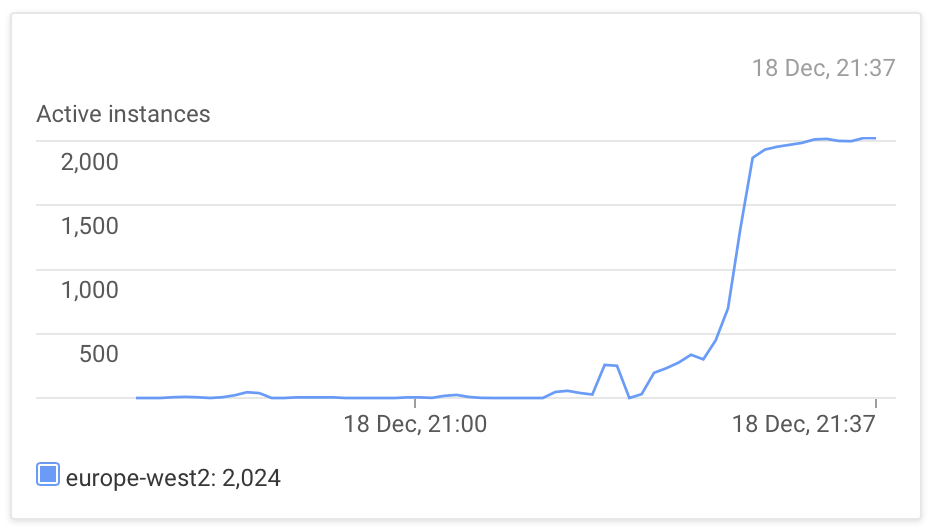
And it worked!

Kind of. Obviously I could have checked things a little before, and an unwatched pi plugged into a random powerboard is not completely reliable. Also, my garden could use some colours other than green, and we can work on something other than auto exposure perhaps. Anyway, onwards!